

1.1数据采集子系统
利用互联网爬虫、公开数据服务接口、动态网站采集与解析、元搜索引擎相结合的方式,采集国际主流与指定国家或地区的区域性主流社交网络媒体、搜索引擎、新闻网站、论坛、博客等平台的公开数据。自动下载与特定账号或特定关键词相关的全量数据(包括文本、图像、视频、属性、关联信息等)并存储,用于后续分析溯源。
1.1.1搜索引擎采集
1) Baidu/文字
2) Google/文字、图像、视频
3) Bing/文字、图像
4) Naver/文字、视频
1.1.2 Twitter数据采集
1)用户信息采集
用户头像URL、用户ID、用户名称、用户昵称、用户描述、用户位置、账号创建时间、关注人数、粉丝人数、发布推文数量、最近发文时间等。
2)发布内容信息采集
推文信息:推文url、发帖作者、推文类型(文字、图片、视频)、推文内容、推文发布时间,是否原创、原创作者ID、点赞数、评论数、转发数以及相对应的用户列表;
详细信息:点赞用户ID;评论用户ID、评论内容、评论时间;转发用户ID、转发内容、分享时间等。
1.1.3 Youtube数据采集
支持频道(专栏)信息、视频标题、描述、发布时间、视频内容、评论等数据采集;支持实时监测指定视频网站点击率,一旦发现某时间内点击率上升最快或点击率最高的视频,立即下载。
1.1.4 LinkedIn数据采集
支持用户账号简历全量信息及动态发布信息采集,组织或单位成员简历全量信息及动态发布信息采集。
具体采集内容包括:头像、用户名、现居地、个人介绍、现任职务、工作地点、毕业院校、联系方式、好友数量;工作经历:入职时间、离职时间、公司名称、职位;学习经历:入学时间、毕业时间、学校、专业、学位;参与项目信息、资格认证、技能认可、语言能力等。
1.1.5 Instagram数据采集
支持用户个人信息,关注好友信息,发布内容(图片、视频),发布时间等信息的采集。
1.2数据清洗子系统
对采集到的冗杂数据进行数据清洗,过滤掉相同和相似数据,提高系统吞吐量;针对去冗余后的图像视频数据,首先对其进行转码,将其转化为系统可处理的格式,然后对视频进行关键帧抽取,将大段视频转化为可代表其主要内容一定数量的图像帧,便于下一步的识别分析。
模块技术方案图如下图所示。核心算法包括两部分:图像特征/指纹提取及引擎检测识别。
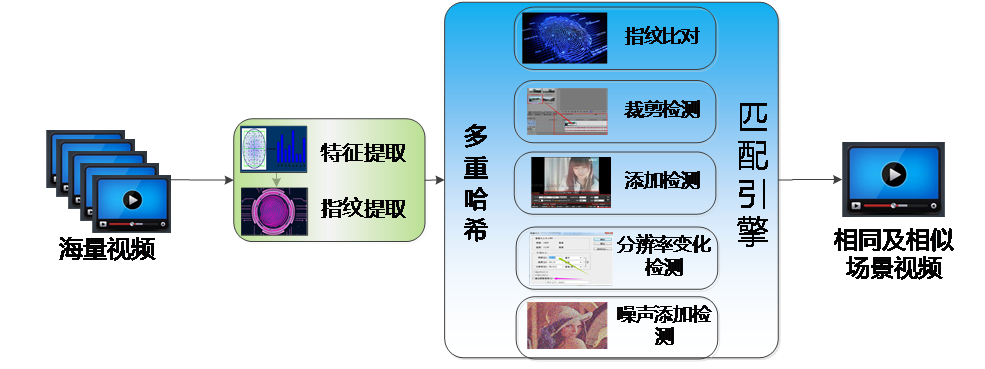
图1 视频/图像预处理流程图
基于哈希的视频特征/指纹提取,针对视频文件,本模块设计基于强哈希、模糊哈希和感知哈希的图像特征、指纹提取算法。
基于强哈希的图像指纹提取算法,对于任意输入视频,通过MD5算法产生该视频的指纹。计算指纹时面对的输入视频数据,由于视频数据因其时长不一,体积可能达到任意大小。因此,若在计算指纹时对所有文件都将其整体作为输入,可能在遇到较大视频时占用很多计算资源,同时影响指纹计算的速度。因此,在实现过程中配置了自适应的指纹生成策略:
1) 对于体积小于阈值的视频数据,则将其整体作为输入进行计算,生成MD5指纹信息;
2) 对于体积大于阈值的视频数据,则取其文件前4096 bits、中4096 bits和尾部4096 bits组合成新的数据,将其作为输入进行计算,生成MD5指纹信息。
基于模糊哈希的特征、指纹提取算法,模糊哈希特征通过分片技术解决传统哈希算法无法处理文件改动的弊端,可用于识别经裁剪、添加后的BK场景图像信息。算法采取四个环节实现特征指纹提取,首先基于Alder-32以及一个分片值实现弱哈希算法,用于文件分片;然后基于Fowler-Noll-Vo hash实现强哈希算法,计算每片哈希值,完成特征提取;最后实现基于FNV哈希算法实现特征压缩映射,完成指纹提取。
基于感知哈希的特征、指纹提取算法,感知哈希特征对图像的尺寸变换,噪声变换具有较强适应性,可用于识别经分辨率变化、噪声变化的BK场面图像信息。算法首先通过尺度缩小、色彩简化最快速去除图像高频细节,摒弃不同尺寸及颜色微变带来的图片差异,然后基于离散余弦变换、低频采样提取图片中的低频信息,去除高频噪声信息的干扰,完成特征提取;最后基于特征均值激活方法将特征映射为64bit的长整形指纹,完成指纹提取。
完成指纹提取后,设计指纹匹配策略如下:
针对强哈希指纹信息,将待测文件MD5值输入已有文件库中进行检索,如果发现完全相同的MD5值,即发现目标文件。
针对模糊哈希指纹信息,基于加权编辑距离实现匹配检测功能。加权编辑距离计算将待匹配的两个字符串(指纹)信息变成相同指纹最少需要多少步操作(包括插入、删除、修改、交换),然后对不同操作给出一个权值,将结果相加获得加权编辑距离,算法然后将加权编辑局里除以两个指纹的长度和,以将绝对结果变为相对结果,再映射到0-100的一个整数值上,其中,100表示两个字符串完全一致,而0表示完全不相似,最后获得相似程度的评分,当评分超过阈值,即发现目标文件。
针对感知哈希指纹信息,计算待匹配的两个字符串(指纹)信息的汉明距离,然后基于汉明距离计算二者相似程度评分。当评分超过阈值,即发现目标文件。
1.3数据分析子系统
数据分析子系统通过数据融合等技术手段,实现对目标人物和目标事件的侦查,快速生成简报或定制专业化报告。
1.3.1目标数据身份落地
针对目标数据进行跨平台融合分析,同时将社交平台中出现的人脸数据与监控视频等非网络数据中的图像视频人脸进行比对,从而将虚拟账号与物理人对应起来,确定目标多重身份。人脸聚类的关键在于将众多不明身份的人脸图片进行身份分析,并将属于同一身份的人脸图片给予相同的身份ID。由于平台图片多不包含直接的身份信息,这里采用基于DBSCAN算法的无监督聚类的技术手段对人脸图片进行聚类,能够解决的已有聚类算法在人脸相似或者比较难分类的情况下,人脸聚类效果不好的问题。
具体步骤如下:
1) 首先进行人脸检测和人脸特征提取。
2) 利用DBSCAN聚类算法对第(1)步提取的人脸特征进行初步聚类。DBSCAN聚类算法有两个参数,分别为距离参数eps和形成高密度区域所需要的最少点数参数minPts。根据实际情况设置minPts参数,比如设置minPts=5,表示一个类中元素个数大于等于5个时,才会被认为是一个有效的类,否则就划分为噪声点。这一步的关键是距离参数eps的设定。这一步中需要将eps值设置小一些,使得聚类算法运行后得到的每一类的纯度尽可能地高,即每一类尽可能都是同一个人的人脸图片。
3) 对第(2)步得到的每一个类,计算类内两两人脸之间的距离,统计距离的中位数,若中位数值大于设定的阈值,则说明该类纯度比较低,即类内包含多个人的人脸。此时需要用DBSCAN聚类算法进一步对该类再次聚类,再次聚类时eps参数需要设置更小,以便可以区分出不同人脸。对二次聚类产生的新的类,标记为难类;若中位数值小于设定的阈值,则说明该类纯度高,类中为同一个人的人脸。对于没有进行二次聚类的类,标记为普通类。
4) 对第(3)步得到的每一个类进行计算中心点。可以只计算每一个类中核心对象的中心点,使得计算出的中心点更加可靠。此处中心点的计算方式为计算每个类中人脸特征在各个维度上的算术平均值。
5) 遍历目前还未被归类的每一个人脸,计算该人脸与第(4)步得到的每一个中心点的距离,在这些距离中取出最小距离,若该最小距离大于设定的阈值,则仍将该点判断为噪声点,即不属于第(4)步得到的任何一个类;若该最小距离小于设定的阈值,则将该点划分到最小距离对应的类中。需要说明的是,对于难类和普通类,上述提到的阈值大小是不同的,难类对应的阈值要比普通类对应的阈值小,即划分到难类的要求更高。
6) 根据第(5)步得到的类,重新计算每一个类的中心点。两两计算类中心点之间的距离,若距离小于设定的阈值,说明这两个类的人脸属于同一个人,则将这两个类合并;若计算得到的距离大于设定的阈值,则说明这两个类的人脸属于不同人的人脸,不进行合并。需要说明的是,普通类与普通类的合并阈值要比难类参与的合并阈值要高一些,即难类参与的合并要求要高。
7) 如果待聚类的人脸数据非常多,那么直接聚类可能导致系统内存不足,因此可以考虑分批次聚类。具体做法为每次取一部分人脸数据按照上述步骤聚类,然后将每次的聚类结果合并到已有的类别上,合并规则为,比较新的类中心点与已有的类中心点之间的距离,若距离小于设定的阈值,则合并;否则就不合并,将该聚类结果保存为新的一个类。
至此完成了基于改进DBSCAN的人脸聚类方法。在人脸聚类后,每个人脸图像都被赋予了一个身份ID,具有同一ID的图像即为同一个人的人脸图像。
1.3.2目标人物关系挖掘
针对目标数据进行跨平台信息采集和融合分析,确定目标人物的身份信息、社交情况、政治倾向等信息,并建立目标区域重点人物数据库。
要接近目标人物,通常需要从其身边人入手,因此分析目标与其他人的通连关系意义重大,包括网络空间人物通连关系和物理空间人物通连关系。其中,网络空间人物通连关系指各社交平台上目标人物账号与其他账号的相互关注关系、转发关系、互动关系(点赞评论)等。可自动化爬取用户的一度、二度、三度好友信息。
1.3.3特定事件侦查分析
可以快速采集指定地区主流网站、论坛、博客以及主流社交网站中的与目标事件相关的文字、图像、视频等信息素材,进行信息智能提取、关联分析和综合研判,针对目标事件在网络上的整体传播情况进行分析,找出传播此信息的源头和传播路径;采集网络中出现的与该事件相关的图像视频信息,落地参与目标事件的人物信息。形成涵盖目标事件简介、热点词、参与人员、传播途径的特定目标数据分析报告。


